拆解 Claude Code:它是怎么在 200K 上下文里"永远不会聊爆"的
Claude Code 能在一个会话里持续工作很久——搜索代码、读文件、改代码、跑测试、看报错、再改——这个过程可能涉及几十轮工具调用。但每一次工具调用的结果都会塞进对话历史:一个 grep 搜索可能返回几千行,一个 cat 可能读出整个文件。不到十轮,200K 的上下文窗口就可能被塞满。
然而你几乎感受不到这个限制。它从来不会突然说”对不起,上下文满了,我们得重新开始”。
源码揭示了背后的机制:一套 6 层渐进式压缩架构,从工具执行的那一刻起就在控制上下文膨胀,直到最终的对话摘要。每一层成本递增、破坏性递增,系统总是优先用最轻量的方式解决问题。
架构全景图
Claude Code 在每次调用 API 之前,会把消息依次送过以下处理管线:

Layer 1: 工具自己管自己
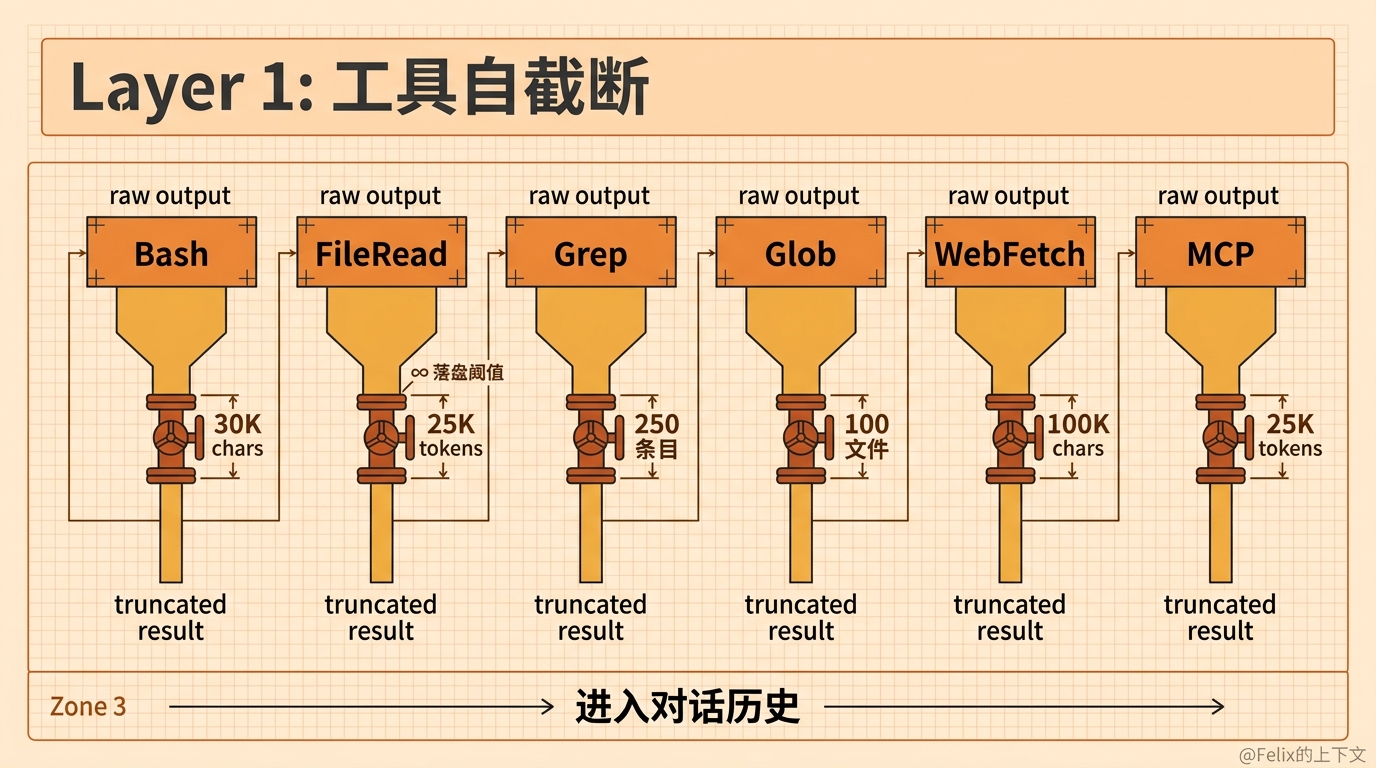
这是最朴素也最有效的第一道防线——每个工具在返回结果的那一刻,就把自己的输出截断了。
以 Bash 工具为例。它的输出上限定义在:
1 | // src/utils/shell/outputLimits.ts |
实际执行时,Bash 用一个 EndTruncatingAccumulator 来收集 stdout,超出上限的部分直接丢弃。如果输出过大,完整内容会被写到磁盘(复用 Layer 2 的落盘机制),模型拿到的是一个 <persisted-output> 预览。模型知道输出不完整,如果需要更多内容,可以用 FileRead 去读落盘文件。
不同工具有不同的截断策略:
| 工具 | 截断方式 | 为什么这么设计 |
|---|---|---|
| Bash | 30K 字符 | 命令输出可能巨大(find /、npm install) |
| FileRead | 25K tokens + 256KB 门槛 | 超大文件先拦住,支持分段读取 |
| Grep | 250 条目 + 20K 字符 | 全局搜索可能匹配几千行 |
| Glob | 100 文件 | 模式匹配可能扫描整个项目 |
| WebFetch | 100K 字符 | 网页 HTML 转 markdown 后仍然很长 |
| MCP | 25K tokens | 第三方工具输出不可控 |
一个细节是 FileRead——它故意把自己的落盘阈值设成了 Infinity,也就是说永远不走 Layer 2 的落盘机制。为什么?因为如果 Read 的结果被存到磁盘文件,模型要看完整内容就得再调一次 Read 去读那个磁盘文件,结果又被存到磁盘……无限套娃。所以 Read 选择用自己的 token 上限来约束输出,而不参与通用的落盘机制。
Layer 2: 大结果落盘,模型只看预览
如果一个工具结果通过了 Layer 1(比如 Glob 返回了 80K 字符的文件列表),但超过了系统级阈值(默认 50K 字符),完整内容会被存到磁盘,模型只看到一个路径和 2KB 的预览。
1 | // src/constants/toolLimits.ts |
模型看到的是这样的东西:
1 | <persisted-output> |
2KB 预览这个数字很精妙——够模型判断”这个结果有没有用”,但不会消耗太多上下文。如果模型确实需要完整内容,它可以用 FileRead 去读那个磁盘文件(并通过 Read 自己的 25K token 限制来控制)。
还有一个重要的细节:文件写入用的是 flag: 'wx'(排他创建模式)。这意味着如果同一个工具结果在后续轮次被重新处理,不会重复写入——幂等性保证。
Layer 3: 防止”并行暴击”
Layer 1 和 Layer 2 都在处理单个工具的输出。但 Claude Code 支持在一次回复中并行调用多个工具——比如同时读 10 个文件,每个返回 40K 字符,合计 400K。单个都没超标,但加在一起就爆了。
Layer 3 解决的就是这个问题:单条消息内所有工具结果的总大小不能超过 200K 字符。
1 | // src/constants/toolLimits.ts |
超了怎么办?按大小降序,把最大的结果存到磁盘(复用 Layer 2 的机制),直到总量回到预算以内。
需要注意的是,Layer 3 的预算执行由 GrowthBook flag tengu_hawthorn_steeple 控制,默认关闭。flag 关闭时,provisionContentReplacementState() 返回 undefined,query.ts 跳过整个预算检查。这意味着目前 Layer 3 对大多数用户来说是不生效的——并行工具结果直接依赖 Layer 1 和 Layer 2 的单工具截断来兜底。
但 Layer 3 最精妙的地方不在预算本身,而在 ContentReplacementState——一个看似简单却影响深远的数据结构:
1 | export type ContentReplacementState = { |
规则只有一条:每个工具结果只有一次被评估的机会,评估结果永远不变。
第一次见到某个工具结果时,系统会判断”要不要落盘”。这个决策一旦做出,就被冻结了——后续轮次遇到同一个结果,不管当前上下文多紧张,都不会重新评估。已经落盘的,每次都用缓存的替换字符串;没有落盘的,以后也永远不会落盘。
为什么要这么”死板”?答案是两个字:缓存。
Prompt Cache——贯穿全文的隐藏主角
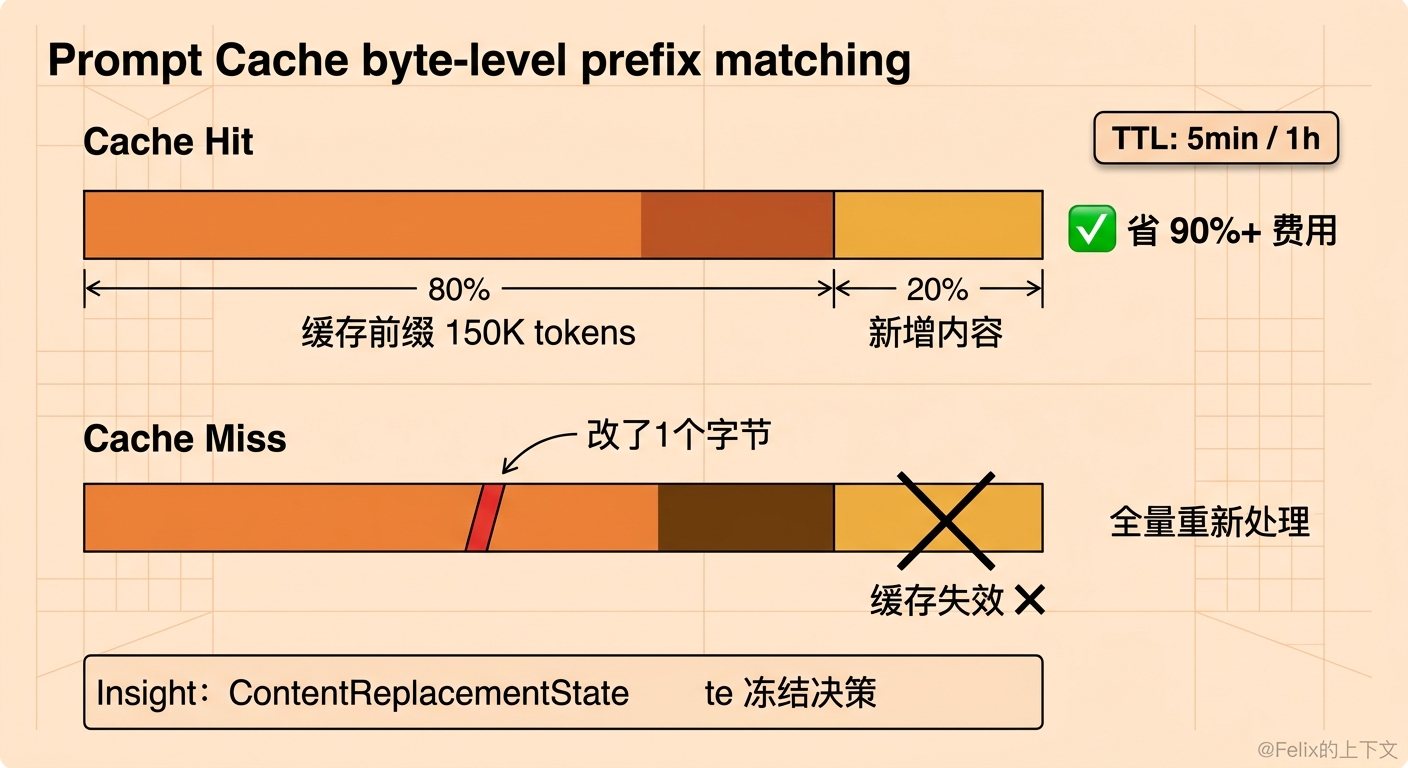
Layer 3 的”冻结决策”看起来很死板,但它背后有一个贯穿 Claude Code 所有压缩层设计的核心约束:Prompt Cache。
每次调用 Claude API,系统提示词、历史消息、工具定义都要重新发送。一个聊了 50 轮的对话,每次都要发几十万 token——既慢又贵。Prompt Cache 的原理是:如果这次请求的前缀和上次字节级相同,API 可以复用缓存,只处理新增的部分。150K token 的对话,缓存命中能省 90% 以上的时间和费用。
缓存有两种 TTL 路径:默认的 5 分钟,以及符合条件时(Anthropic 订阅用户或 Bedrock 用户 opt-in)可激活的 1 小时 TTL。getCacheControl() 函数通过 should1hCacheTTL() 条件判断是否给缓存标记 ttl: '1h'。前面时间触发微压缩选择 60 分钟阈值,正是与 1 小时 TTL 对齐——确保即使是最长的缓存也已经失效。
但不管 TTL 是 5 分钟还是 1 小时,”字节级相同”这个要求都极其苛刻——改了前缀中的一个字符,整个缓存就废了。
这就是 ContentReplacementState “冻结决策”的原因。假设 Layer 3 在第 10 轮决定保留某个 Grep 结果(40K),到第 20 轮上下文紧张了又把它换成预览(2KB),那从第 11 条消息开始的所有内容都变了——缓存全部失效。
Prompt Cache 这个约束深刻地影响了后面每一层的设计。所有的压缩操作要么只动”新增内容”(不影响缓存前缀),要么在缓存已经失效的情况下才执行,要么通过特殊 API 在服务端完成编辑。
Layer 4: 微压缩——精打细算的清理工
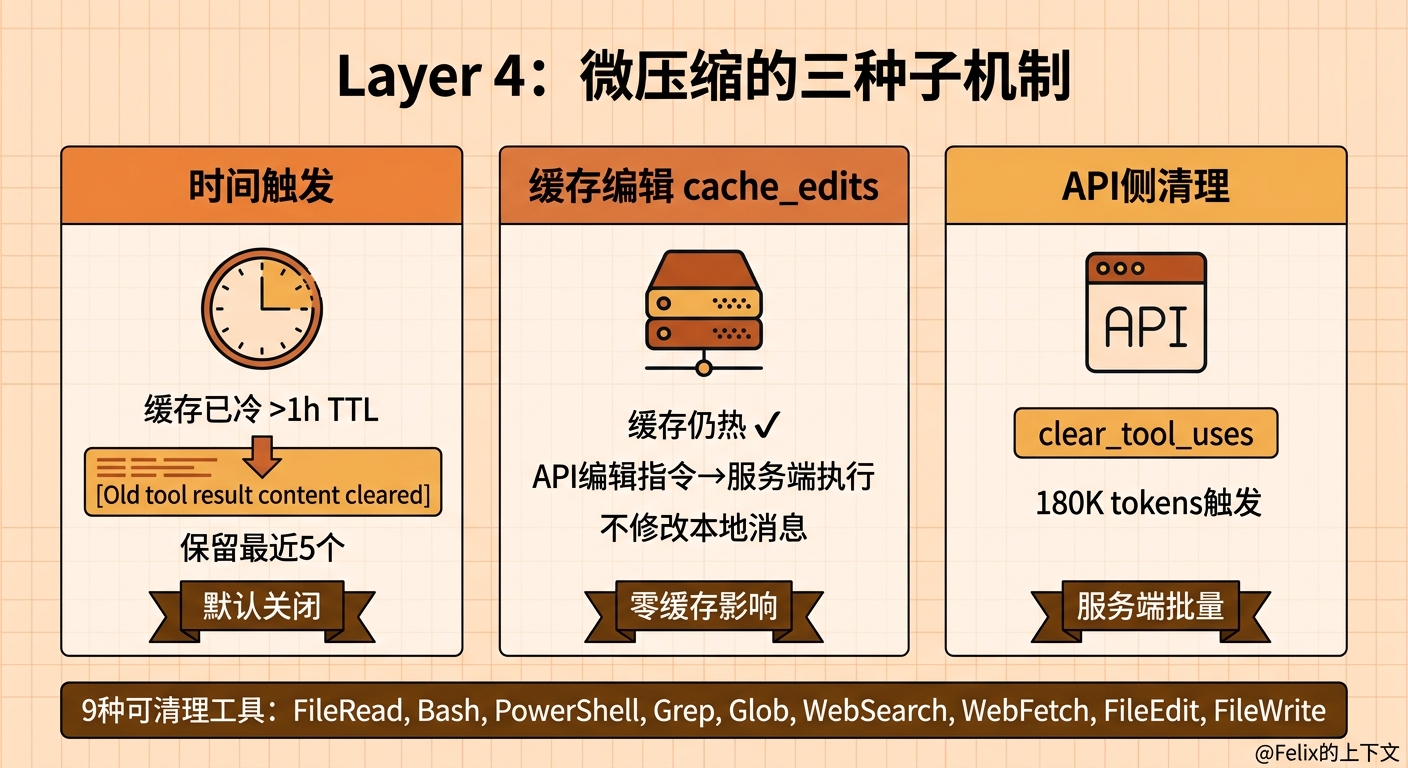
前三层处理的都是”新产生的工具结果太大”的问题。但还有另一种情况:旧的工具结果在上下文里待了很久,早就没用了,但还在占空间。
你 20 分钟前搜索的那个 Grep 结果,10 分钟前读的那个配置文件内容——现在你已经在改另一个模块了,它们就是死重量。
微压缩就是来清理这些死重量的。它有三种子机制,其中最有代表性的是时间触发微压缩。
时间触发:你不在的时候帮你收拾桌子
当你离开电脑一段时间(默认 60 分钟)再回来时,微压缩会把旧的工具结果内容清掉,只保留最近 5 个:
1 | // src/services/compact/microCompact.ts |
被清理的工具结果变成了一行字:[Old tool result content cleared]。模型知道”这里曾经有个工具结果,但内容不重要了”。
为什么选 60 分钟? 因为源码注释中提到的是服务端的 1 小时 Cache TTL("the server's 1h cache TTL is guaranteed expired")。你离开 60 分钟回来,缓存必然已经冷了——反正下次请求要重新处理整个前缀,不如趁机瘦身。这就是为什么时间触发微压缩敢直接修改消息内容(破坏缓存前缀)——因为缓存已经不存在了。
不过需要注意,时间触发微压缩在当前代码中默认是关闭的(enabled: false),由 GrowthBook 远程控制开启。
缓存编辑:缓存热的时候也能瘦身
如果你一直在活跃使用(缓存是热的),但工具结果积累了很多,直接修改消息内容会破坏缓存,代价太大。Claude Code 用了一个巧妙的方式——cache_edits:
不修改本地消息,而是在 API 请求中附带一组”编辑指令”,告诉服务端:”请在你的缓存里把这几个工具结果删掉”。服务端在缓存层面执行编辑,不需要客户端重新发送完整前缀。
这就像在图书馆里,你不需要把书搬出来再搬回去才能撕掉某一页——图书馆员可以直接在书架上操作。
只清理 9 种工具
注意 COMPACTABLE_TOOLS 这个集合——只有 9 种工具的结果会被清理(包括 Windows 上的 PowerShell)。像 Agent(子代理)的结果、MCP 工具的结果就不会被动。
这是一个保守但明智的选择:Read、Grep、Bash 的结果都是可重新获取的(再搜一次、再读一次就行),但 Agent 的长篇分析、MCP 工具的外部数据可能不可重现。宁可少清一些,也不冒丢失关键信息的风险。
Layer 5: 结构化剪裁(仅管线骨架,实现为 stub)
Layer 5 在 query.ts 中有完整的调用骨架(feature flag 判断 + 函数调用),但在当前开源代码中,两个实现都是 stub:
- Snip(
snipCompact.ts):文件首行注释为"Auto-generated stub",snipCompactIfNeeded直接返回原始消息,不做任何操作。 - Context Collapse(
contextCollapse/index.ts):同样是 stub,isContextCollapseEnabled()固定返回false。
从管线骨架可以推测它们的设计意图:Snip 用于整组删除旧消息,Context Collapse 用于对历史消息投影折叠视图(类似 IDE 的代码折叠)。管线代码中有一个有意思的设计:当 Context Collapse 启用时,它会抑制 Layer 6 的全量压缩——两者不能同时工作,因为它们会在阈值附近互相干扰。
但就当前代码而言,Layer 5 是不生效的。实际的上下文管理落在 Layer 4 和 Layer 6 上。
Layer 6: 最终手段——把整本笔记浓缩成一页摘要
当前面所有轻量级手段都无法阻止上下文持续增长时,Layer 6 登场——调用 AI 把整个对话历史压缩成一段结构化摘要。
触发阈值
1 | // src/services/compact/autoCompact.ts |
以 200K 上下文模型为例:

为什么要留 13K 的缓冲区?因为 token 计数不是实时精确的——它用的是混合估算:最后一次 API 返回的真实 token 数 + 之后新增消息的粗略估算(每 4 个字符 ≈ 1 token)。缓冲区就是为了对冲这个估算误差。
先试零成本方案
触发压缩时,Claude Code 不会立即调用 API。它先尝试一个零成本方案——Session Memory Compact:
在会话过程中,系统会在后台异步提取一份”会话记忆”文件(类似笔记摘要)。如果这份文件质量够好,就直接拿它当摘要用,不需要任何额外的 API 调用。
这个功能同样由 GrowthBook 控制——需要 tengu_session_memory 和 tengu_sm_compact 两个 flag 同时开启才能生效。当前默认关闭,所以大多数场景下会直接走完整 API 摘要路径。

完整 API 摘要:一个 9 段结构化模板
如果零成本方案不行,就得认真做一次 AI 摘要了。Claude Code 不是简单地说”请总结以上对话”——它用了一个精心设计的 9 段结构化模板:
1 | 1. 主要请求和意图 — 用户到底想干什么? |
其中第 6 条”所有用户消息”特别关键——它要求摘要逐条列出用户说过的每一句话。这是为了防止一个微妙的问题:经过多轮压缩后,模型可能”忘记”用户最初的意图,或者把两个不同的请求混为一谈。逐条保留用户消息就是在说”不管怎么压缩,用户的原话不能丢”。
摘要的生成过程也有讲究。模型先在 <analysis> 标签里打草稿(思考过程),再在 <summary> 标签里写正式摘要。<analysis> 部分在摘要进入上下文之前会被整段剥离——它是消耗品,用完即弃。这就是典型的”花 token 买质量”的做法。
压缩后的”善后工作”
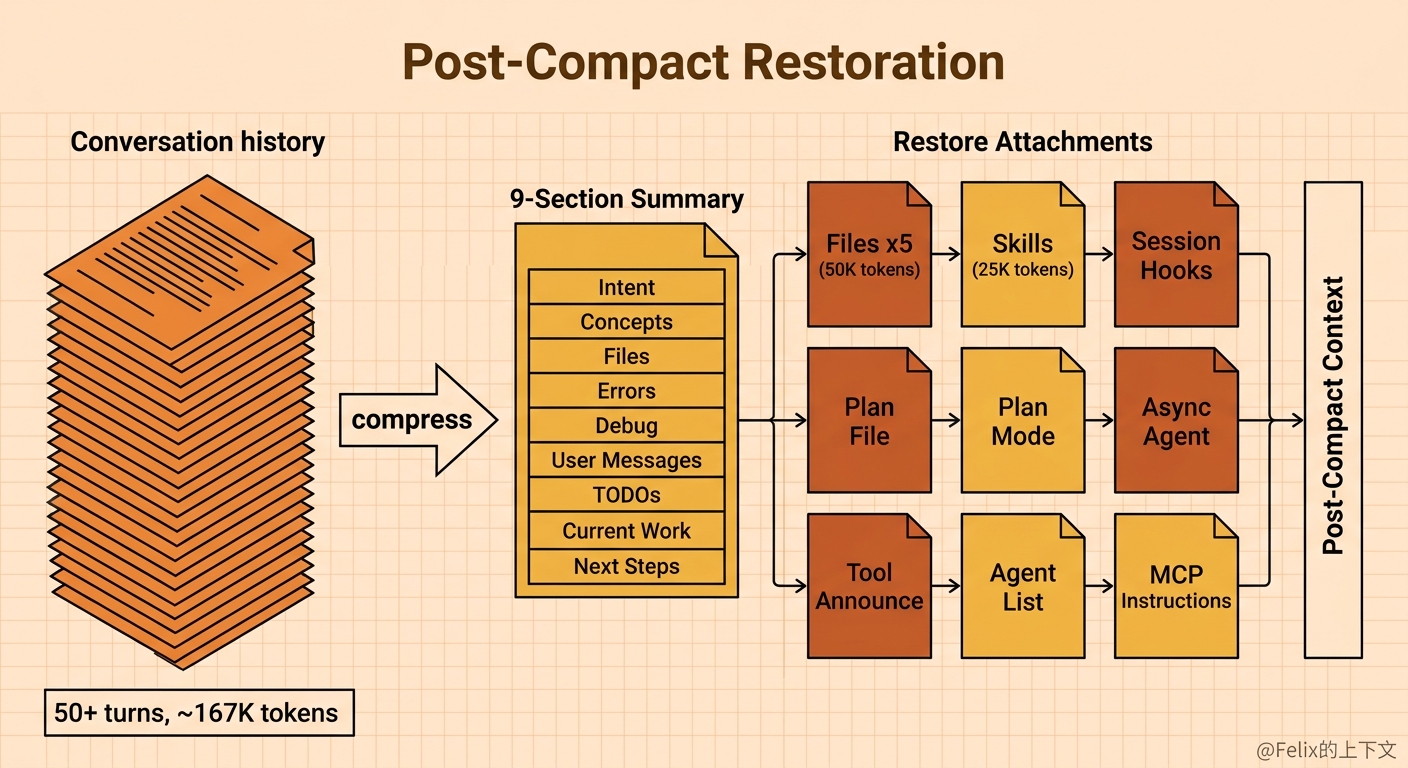
压缩不是把旧消息变成摘要就完了。Claude Code 还有一套详尽的善后流程:
1 | // src/services/compact/compact.ts |
它会:
- 重新读取最近 5 个文件——压缩把文件内容丢了,但模型很可能马上就要用。与其等模型自己去 Read,不如主动恢复
- 重新注入技能定义——slash commands 的说明文档
- 重新执行 session start hooks——比如重新加载 CLAUDE.md 的内容
- 重新公告可用工具列表——确保模型知道有哪些工具可用
为什么限制”最多 5 个文件,每个最多 5K tokens”?因为压缩的目的是腾出空间。如果善后工作本身就塞进去太多东西,那压缩等于白做了。文件恢复的预算是 50K tokens,技能恢复另有 25K tokens 的独立预算。除此之外,还有 plan 文件、plan mode 指令、异步 agent 附件、延迟工具公告、agent 列表公告、MCP 指令公告、session start hooks 等附件——总共 9 类后处理附件,每类按需注入。
图片在摘要时直接丢弃
图片在上下文中占据大量 token(一张截图可能值几千 token),但对生成文字摘要毫无帮助。所以在发送摘要请求之前,Claude Code 会把所有图片和文档替换成文字标记:
1 | // src/services/compact/compact.ts |
摘要模型只需要知道”这里有张图”就够了。
共享 Prompt Cache 的巧妙做法
摘要请求本身也要调用 API,上下文不也很大吗?Claude Code 的优化方式是Forked Agent:
1 | const result = await runForkedAgent({ |
Forked Agent 复用主对话的 Prompt Cache——系统提示词、工具定义、历史消息都已经在缓存里了,摘要请求只需要追加一条”请总结”的消息。这样一次摘要可能只需要为新增的那几百个 token 付费,而不是为整个 150K+ 的上下文付费。
熔断器:防止无限重试
如果摘要请求因为各种原因失败了(API 超时、输出质量不佳等),系统最多重试 3 次就放弃:
1 | // src/services/compact/autoCompact.ts |
注释里的数据很惊人——在加入熔断器之前,有些会话会疯狂重试压缩(最多 3,272 次),全球每天浪费 25 万次 API 调用。这是一个典型的”在生产中发现的教训”。
query.ts 中的管线编排
这些层在代码中是怎么串起来的?在 src/query.ts 的每次 API 调用前,有一段约 100 行的管线代码。注意,代码中的执行顺序和前文的 Layer 编号并不一致——Layer 编号按成本/破坏性递增排列(便于理解设计哲学),而实际执行顺序是按实现依赖关系编排的:
1 | // Step 1: 单消息聚合预算 [Layer 3] |
五步处理,每步的输出是下一步的输入。每一步都可能让上下文缩小,如果前面的步骤已经足够,后面的就会发现”不需要压缩”然后直接跳过。
一个细节:snipTokensFreed 被传递给了 autocompact。这是因为 snip 删除了旧消息,但 token 计数是基于上次 API 返回的 usage 数据——那个数据不知道有些消息已经被删了。所以 snip 需要告诉 autocompact “我已经省了这么多,你别算重了”。
完整的画面
回到最初的问题:Claude Code 为什么能在一个会话里持续工作那么久?不是靠一个”大招”,而是靠6 层渐进式防线:
| 层级 | 什么时候生效 | 破坏性 | 成本 |
|---|---|---|---|
| Layer 1: 单工具截断 | 工具执行完毕时 | 最低——只截断当前结果 | 零 |
| Layer 2: 大结果落盘 | 工具执行完毕时 | 低——完整内容还在磁盘上 | 一次磁盘写入 |
| Layer 3: 聚合预算 | 每次 API 调用前 | 低——同上 | 可能的磁盘写入 |
| Layer 4: 微压缩 | 每次 API 调用前 | 中——旧结果内容被清除 | 零或一次 cache_edit |
| Layer 5: 结构化剪裁 | 每次 API 调用前 | 中——旧消息被移除或折叠 | 零(当前为 stub) |
| Layer 6: 全量摘要 | 每次 API 调用前 | 高——整个历史变成一段摘要 | 一次额外 API 调用 |
而Prompt Cache 的稳定性是贯穿所有设计的隐藏约束——ContentReplacementState 的冻结、微压缩的三种子策略选择、甚至管线的执行顺序,都是为了尽量不破坏缓存前缀。
这套系统的本质思想可以用一句话概括:用最小的代价,尽可能晚地动用最重的手段。它不是在上下文满的时候才开始想办法,而是从第一个工具结果产生的那一刻起,就已经在精打细算了。
Claude Code 那个”永不停下”的 Agent Loop 之所以能真正跑起来,正是因为背后有这套系统在确保它永远有足够的空间继续工作。